Step 2: Automate data ingestion
This is the second step of the magasin getting started tutorial. In this step we will see how to automate the data ingestion.
In the previous step, we delved into the DPG Alliance API data, generating graphs and uncovering insights along the way.
1 Background
Typically, after identifying intriguing insights, it’s common as next step to periodically update the data to monitor the evolution of the data.
Automating this process is highly advantageous as it eliminates the need for repetitive tasks. In our scenario, the workflow involves fetching data from the DPG API, followed by cleaning and processing it for seamless integration with a business intelligence dashboard creation tool, Superset, that will be used in the next step.
The good news is that we have already completed the heavy lifting using the Jupyter Notebook. This is advantageous because the code we will be writing is essentially the same; we just need to make some tweaks to adapt it into a Dagster pipeline.
1.1 Advantages of using Dagster
Dagster is what is known as a pipeline orchestrator, which essentially helps us manage the ingestion of data from multiple sources.
The benefits of using a framework like Dagster are manifold. It allows us to approach tasks in a structured manner, facilitating scalability and monitoring. Anyone who has dealt with gathering data from multiple sources will attest that it can quickly turn into a nightmare if not managed properly. Dagster provides an excellent starting point for tackling such challenges.
What usually happends when you start automating gathering data, processing and mixing data from multiple data sources is that:
It begins simple but with time it becomes more complex. You add more and more data sources, more logic to clean the data, stablish more dependencies between the data sources, etc. If this is not done properly you end up with a mess. Dagster provides us a framework that helps to write our code in a more structured way, as well as tools to debug and monitor the ingestion of the data.
It eventually may break. Data sources may change with time and with that your pipelines break. For instance, DPGA may change the API unexpectedly, and with that our automation will fail too. Dagster allows you to monitor failures as well as to debug where it failed.
Another advantage of Dagster, it that it uses Python as programming language, so, as we said earlier, most of the work we did for the Jupyter Notebook can be reused.
1.2 Storing data as parquet files
In the magasin architecture, as general approach, we stand to store data assets as files. In particular, we recommend the use of Apache parquet file format.
The main reason to use files is:
First, because it is an economic way to store data. Storage services in the cloud or in premises is relatively cheap.
Second, because it does provide more flexibility when changes on the underlying structure are introduced, at least compared with setting up a SQL database downstream.
In addition, it allows also to easily store more types of data such as documents or images. Lastly, in terms of governance and sharing the datasets, the problem is simplified to setting up file sharing permissions.
1.3 Parquet format for structured data.
Parquet is a columnar storage file format that is commonly used in the Big Data ecosystem. It is designed to efficiently store and process large amounts of data.
Using Parquet to store processed datasets is beneficial because it optimizes storage, improves query performance, and enhances the overall efficiency of data processing. Its compatibility with popular Big Data processing frameworks and support for schema evolution make it a versatile choice for storing large-scale, evolving datasets in data lakes and data warehouses.
1.4 MinIO, magasin’s storage layer (optional)
For keeping a consistent approach across the different cloud providers, magasin includes a component called MinIO. It gives an Amazon S3 compatible file (object) store.
Thanks to MinIO, regardless of what infrastructure you’re using, your pipelines will work the same, you do not need to adapt how you store the data if you move to another provider.
Whereas to maintain a vendor-agnostic architecture we leverage MinIO. You have the flexibility to bypass this component if you find alternative methods more suitable for storing your ingested data. This decision may be based on better alignment with your existing processes or specific use case requirements.
For instance, instead of MinIO, you can directly utilize a vendor-specific object store like Azure Blobs, Amazon S3, or Google Cloud Storage. Alternatively, in contrast to the file-storage approach of the datasets you may choose to write your data directly into a database, such as DuckDB or PostgreSQL.
For the purposes of this tutorial we will be using MinIO. And the first step is to setup a bucket. A bucket is somewhat similar to a folder.
So, let’s start creating our pipeline.
You have available the source code of the complete project in magasin’s source code repository within the folderexamples/dpga-pipeline
2 Create a bucket in MinIO
The first thing we need to do is to setup where we are going to store our data. Till now, we’ve been storing the data in our Jupyter lab space, but we need a place where we can securely save our datasets and access them through a standard API that is widely supported by other tools and libraries. MinIO is the component that will give us those capabilities.
First, we are going to launch the MinIO API. This will forward a connection to our localhost:9000 from the MinIO API server in our cluster. This API allows us to interact with the MinIO storage accounts. In our case, we will use the MinIO client mc command line . mc is a tool similar to mag, but specific for MinIO. It is installed during the magasin installation.
mag minio apiKeep this running. In another terminal run this command:
mc alias set myminio http://localhost:9000 minio minio123
# mc alias set <alias-name> <endpoint> <access-key> <secret-key>Added `myminio` successfully.Now, stop mag minio api command using Control + C.
Once we have configured the alias, we just need to create the bucket:
mag minio add bucket --bucket-name magasin Note that the default alias that mag asumes will be myminio. If you used another alias you can use --alias option. For example:
mag minio add bucket --bucket-name magasin --alias myaliasAt this point, we have a bucket in MinIO which allows us to store files and access them through standard APIs.
mag allows you to shorten the commands using the alias. For example:
mag minio add bucket --bucket-name magasin --alias myalias`can be written as
mag m a b -b magasin -a myaliasUsing the shorten version is a way of speeding up your interaction with the command, but it is less readable, so in this tutorial we will stick to the long version.
To get to know what are the available alias type mag --help or mag <command> --help you can see the shortcut versions in parenthesis.
mag --helpUsage: mag [OPTIONS] COMMAND [ARGS]...
...
Commands:
dagster (d) Dagster commands
daskhub (dh) Daskhub/Jupyterhub commands
drill (dr) Apache Drill commands
minio (m) MinIO commands
superset (ss) Apache Superset commandsHere you can see that daskhub shortcut is dh and minio is m
3 Create a Dagster pipeline
The next step is to create a pipeline using Dagster. A pipeline is just a piece of code that moves data from place to another and that can introduce some changes before saving it in the destination place. In our case the pipeline will take the data from the DPGA API and store it in a MinIO bucket.
The first thing we need to do is to install Dagster.
pip install dagster==1.9.3 dagster-webserver==1.9.3Dagster is a very agile product that is continuously evolving, this means that you have to be cognizant of the version you’re running.
You can check the version installed in your cluster by running helm list --all-namespaces and looking at the APP VERSION column.
Then run pip install pip install dagster==<version>
3.1 Add the pipeline code
Once Dagster is installed, we’re going to create a new project using the default structure prodivded by Dagster. This should be the default procedure for creating any new pipeline.
dagster project scaffold --name dpga-pipelineCreating a Dagster project at /home/magasin/dpga-pipeline.
Creating a Dagster code location at /home/magasin/dpga-pipeline.
Generated files for Dagster code location in /home/magasin/dpga-pipeline.
Generated files for Dagster project in /home/magasin/dpga-pipeline.
Success! Created dpga-pipeline at /home/magasin/dpga-pipeline.By scaffolding our project, Dagster creates a basic structure of a python package that could be installed using pip as any other package as well as some additional metadata files that will be used by Dagster to run the pipeline. You have some more info in the Dagster documentation.
Now, lets add our code. Open the file dpga-pipeline/dpga_pipeline/assets.py
dpga-pipeline/dpga_pipeline/assets.py
import requests
import pandas as pd
from pandas import DataFrame
from dagster import asset
@asset
def raw_dpgs() -> DataFrame:
""" DPGs data from the API"""
dpgs_json_dict = requests.get("https://app.digitalpublicgoods.net/api/dpgs").json()
df = pd.DataFrame.from_dict(dpgs_json_dict)
return df
@asset
def deployment_countries(raw_dpgs: DataFrame) -> DataFrame:
df = raw_dpgs
df_loc = pd.merge(df, pd.json_normalize(df["locations"]), left_index=True, right_index=True)
df_deployment_countries = df_loc.explode("deploymentCountries")
df_deployment_countries[["name","deploymentCountries"]]
return df_deployment_countriesAs you can see the code seems pretty similar to what we wrote in our exploratory analysis.
The in the code we have defined two @assets. An asset according to the Dagster definition is:
An asset is an object in persistent storage, such as a table, file, or persisted machine learning model. A Software-defined Asset is a Dagster object that couples an asset to the function and upstream assets used to produce its contents.
In our case, raw_dpgs, stores the dpgs as they come from the API as a DataFrame, and deployment_countries that extracts the one row per country in which the DPG has been deplayed.
Another thing that you can notice in the code is that in the definition of the deployment_countries asset, we are passing raw_dpgs: DataFrame. That will tell Dagster that deployment_countries depends on the raw_dpgs and it will be used as input.
As you noticed, we are using a couple of packages that need to be installed pandas and requests. To install them, in dpga-pipeline/setup.py we add them in the install_requires array.
dagster-pipeline/setup.py
setup(
# ...
install_requires=[
"dagster",
"dagster-cloud",
"pandas", # <--- Add this line
"requests" # <---- Add this line too
],
#...
)Ok, so now let’s test if this is working so far. To do that we will first install the pipeline package in editable mode (-e). This allows you to edit the package without needing to install it again.
pip install -e '.[dev]'Then, we will launch the Dagster user interface:
dagster devThis launches a local instance of dagster server in port 3000 on localhost. So just open http://localhost:3000. Note, instance of dagster is similar to what you are running on the cluster but directly on your computer. In this case you are not using the one installed in the cluster.
You should see something like:
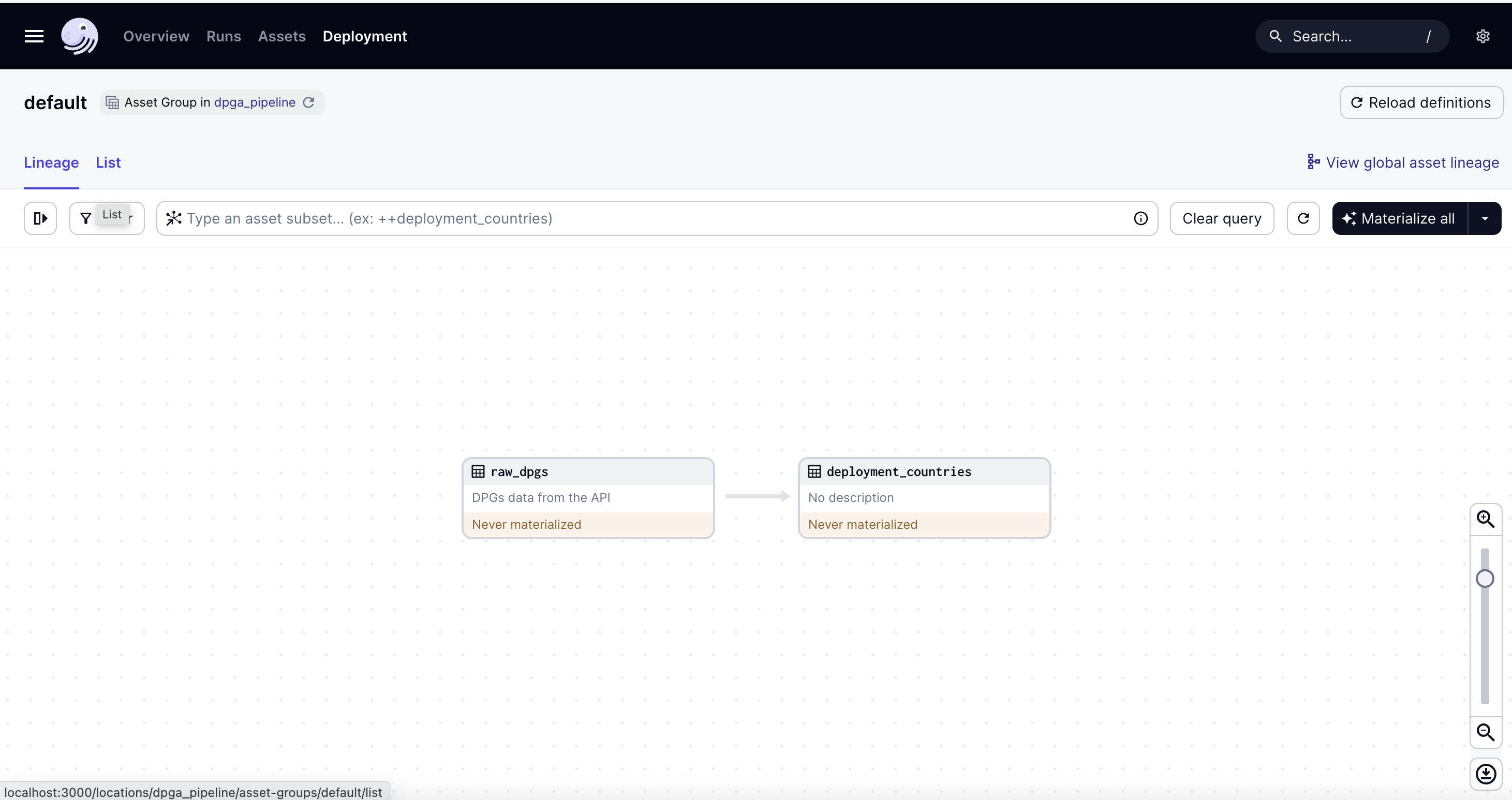
You have available the source code of the pipeline in magasin’s source code repository within the folder examples/dpga-pipeline/dpga-pipeline-store-local
3.1.1 Save the assets in MinIO.
Till now, we’ve been working on the development machine file system. The next step is to save the information we want to keep in MinIO.
To access the MinIO bucket we will use fsspec. This python library provides an standard interface regardless of the underlying filesystem. So, if you chose to use other file system to run this example, you can just change the environment variables and the address.
MinIO provides an S3 compatible bucket file system, so we will use it. First we will add the dependencies fsspec and s3fs.
dpga-pipeline/setup.py
setup(
#...
install_requires=[
"dagster",
"dagster-cloud",
"pandas",
"requests",
"fsspec", # <---- New dependency
"s3fs" # <---- New dependency
],
#...
)Now, we’re going to modify our assets to use the minio filesystem.
dpga-pipeline/dpga_pipeline/assets.py
import fsspec
import requests
import pandas as pd
from pandas import DataFrame
from dagster import asset
@asset
def raw_dpgs() -> DataFrame:
""" DPGs data from the API"""
# Load from API
dpgs_json_dict = requests.get("https://app.digitalpublicgoods.net/api/dpgs").json()
# Convert to pandas dataframe
df = pd.DataFrame.from_dict(dpgs_json_dict)
return df
@asset
def deployment_countries(raw_dpgs: DataFrame) -> DataFrame:
df = raw_dpgs
df_loc = pd.merge(df, pd.json_normalize(df["locations"]), left_index=True, right_index=True)
df_deployment_countries = df_loc.explode("deploymentCountries")
df_deployment_countries = df_deployment_countries[["id", "name","deploymentCountries"]]
# Save to MinIO
fs= fsspec.filesystem('s3')
with fs.open('/magasin/data/deployment_countries.parquet','wb') as f:
df_deployment_countries.to_parquet(f)
return df_deployment_countriesThen, we will setup some environment variables that will setup the Minio S3 bucket credentials. Add the .env file in the root of your project (same folder as setup.py).
FSSPEC_S3_ENDPOINT_URL='http://localhost:9000'
FSSPEC_S3_KEY='minio'
FSSPEC_S3_SECRET='minio123'As you can see we are indicating in the .env file that the endpoint of our minio is in localhost port 9000. To enable this service we need to run the following command
mag minio apiAs earlier, while this command is running it will forward any connection in our localhost:9000 to the our MinIO instance in the Kubernetes cluster. You shoud keep running during this till you are instructed to do close it.
In another terminal, we need to reinstall the pipeline so the new dependencies are loaded, and, then, we can run Dagster:
pip install -e '.[dev]'
dagster devNote that after you launch dagster dev you should see something like:
dagster - INFO - Loaded environment variables from .env file:
FSSPEC_S3_ENDPOINT_URL,FSSPEC_S3_KEY,FSSPEC_S3_SECRETThis is because Dagster loads all the .env file automatically and exposes the variables to the code.
Open again the browser pointing to http://localhost:3000 and in the dagster UI and run Materialize all.
This time, all files should have been materialized in the magasin bucket.
To test if the files are there. In a terminal run:
mc ls myminio/magasin/data3.2 Adding a job scheduler
Until now, we have been materializing manually our assets. However, automating this task is indeed the ultimate goal of setting up a pipeline.
In Dagster, you have available schedulers which basically run your pipeline, or pieces of it, in a fixed interval. Dagster schedulers follow a cron style format.
dpga-pipeline/dpga_pipeline/assets.py
#__init__.py
from dagster import Definitions, load_assets_from_modules, define_asset_job, ScheduleDefinition
from . import assets
all_assets = load_assets_from_modules([assets])
# Create an asset job that materializes all assets of the pipeline
all_assets_job = define_asset_job(name="all_assets_job",
selection=all_assets,
description="Gets all the DPG assets")
# Create a scheduler
main_schedule = ScheduleDefinition(job=all_assets_job,
cron_schedule="* * * * *"
)
defs = Definitions(
assets=all_assets,
jobs=[all_assets_job],
schedules=[main_schedule]
)What we did in the code above is to:
Add a
job. A job, is basically a selection of assets that will be materialized together in the same run.Define a schedule. The schedule will launch the job at specified time intervals. In our case every minute (
* * * * *).
The job cron format is used to specify the schedule for recurring tasks or jobs in Unix-like operating systems and cron job scheduling systems. It consists of five fields separated by spaces, representing different aspects of the schedule:
<minute> <hour> <day-of-month> <month> <day-of-week>Minute (0-59): Specifies the minute of the hour when the job should run. Valid values range from 0 to 59.
Hour (0-23): Specifies the hour of the day when the job should run. Valid values range from 0 to 23, where 0 represents midnight and 23 represents 11 PM.
Day of Month (1-31): Specifies the day of the month when the job should run. Valid values range from 1 to 31, depending on the month.
Month (1-12): Specifies the month of the year when the job should run. Valid values range from 1 to 12, where 1 represents January and 12 represents December.
Day of Week (0-7): Specifies the day of the week when the job should run. Both 0 and 7 represent Sunday, while 1 represents Monday, and so on, up to 6 representing Saturday.
Each field can contain a single value, a list of values separated by commas, a range of values specified with a hyphen, or an asterisk (*) to indicate all possible values. Additionally, you can use special characters such as slashes (/) for specifying intervals and question marks (?) for leaving a field unspecified (e.g., for day of month or day of week when the other field should match).
Here you have some examples of cron intervals
| Cron Expression | Description |
|---|---|
0 0 * * * |
Run a task every day at midnight (00:00). |
15 2 * * * |
Run a task at 2:15 AM every day. |
0 0 * * 1 |
Run a task every Monday at midnight (00:00). |
0 12 * * 1-5 |
Run a task every weekday (Monday to Friday) at 12 PM (noon). |
*/15 * * * * |
Run a task every 15 minutes. |
0 */2 * * * |
Run a task every 2 hours, starting from midnight. |
30 3 * * 6 |
Run a task every Saturday at 3:30 AM. |
0 0 1 * * |
Run a task at midnight on the first day of every month. |
0 0 1 1 * |
Run a task at midnight on January 1st every year. |
If you launch again dagster dev and you go to Overview -> Jobs, you can enable the job.
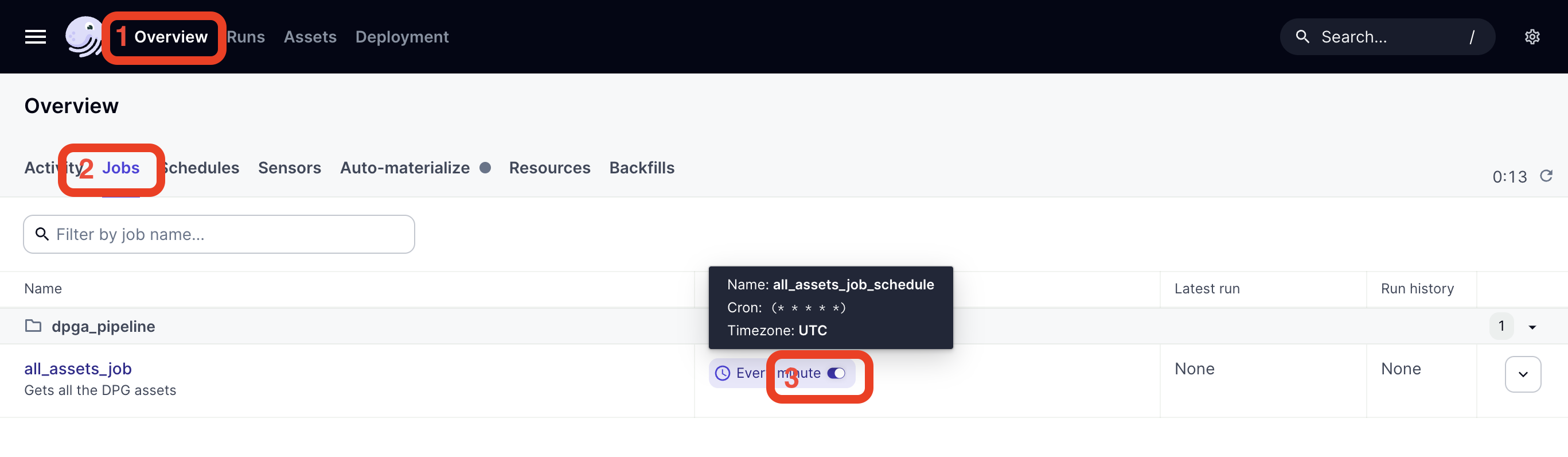
3.3 Deploy the pipeline in the cluster
Until now we have been running dagster on our own computer by enabling the access to the MinIO installed in our kubernetes cluster through mag minio api. But we want our pipeline to run entirely within our Kubernetes cluster. To do that we will deploy a container (pod) in our cluster that Dagster will use to run our pipeline.
We will follow this steps:
Prepare the Docker image. Our pipeline will reside in a container that will be called by Dagster to run the pipeline. So we need to create a Docker image that will hold all our code and is ready to be called by Dagster.
Add the environment variables as secrets. We need to provide to our image the environmental variables. In Kubernetes this is done through secrets. Secrets are a special type of resource for holding sensitive information that exists in Kubernetes.
Re-Deploy Dagster. After we have prepared our image with the pipeline, we need to tell our Dagster instance to deploy it, and use it. The simplest way is to re-deploy magasin’s dagster helm chart.
3.3.1 Prepare the Docker image
Edit the setup.py file of your project and add a new dependency dagster-postgres:
dpga-pipeline/setup.py
from setuptools import find_packages, setup
setup(
name="dpga_pipeline",
packages=find_packages(exclude=["dpga_pipeline_tests"]),
install_requires=[
"dagster",
"dagster-cloud",
"dagster-postgres", #<------------- Add this line
"pandas",
"requests",
"fsspec",
"s3fs"
],
extras_require={"dev": ["dagster-webserver", "pytest"]},
)This is because now Dagster is going to use now the PosgreSQL database that is used in the cluster for keeping the logs data. Earlier, when we were using the local Dagster setup.
In the same folder as the setup.py file of your dagster project create a new file called Dockerfile and add the following.
dagster-pipeline/Dockerfile
# Select the base image
FROM python:3.10-slim
# Copy all our code into the container
COPY . /
# Install the module within the container
# This will install all the dependencies
RUN pip install .Now we are going to build the image. To prevent issues while running it, we are going to build a multi-architecture image. Currently, there are two major architectures we have to deal with ARM64 (RaspberryPi’s and Apple M1/M2…) and AMD64 (regular Intel and AMD computers). By building a multi-architecture image it will run regardless of the architecture.
If you’re use to create Docker images, something that you may have noticed is that in our Dockerfile we did not define an ENTRYPOINT or launched command CMD, in our Dockerfile basically we just installed our pipeline code. Whereas in Docker it is common to end the Dockerfile with one of these two commands, in our case the command that launches dagster will be injected during the deployment of the image. We will set it up later.
# first we create a builder. This just allows us to build for architectures different that our owns.
# This only needs to be run once per computer.
docker buildx create --driver=docker-container --name=magasin-builder
# In the command below replace <registry> by your registry.
# If you are using docker hub, it is your user name (you need to login first.
# In other registries such as Azure Container Registry (my-registry.azurecr.io)or Amazon ECR, please check the documentation of the provider.
docker buildx build --builder=magasin-builder --platform linux/amd64,linux/arm64 -t <registry>/dpga-pipeline:latest --push .Now in our registry we have a new image dpga-pipeline with the tag latest. Note that this image will be publicly available.
For the rest of the tutorial we will use this image: merlos/dpga-pipeline:latest, you can replace it with yours.
If you want to check what other architectures are supported run:
docker buildx lsNAME/NODE DRIVER/ENDPOINT STATUS BUILDKIT PLATFORMS
magasin-builder docker-container
magasin-builder0 desktop-linux running v0.12.3 linux/arm64, linux/amd64, linux/amd64/v2, linux/riscv64, linux/ppc64le, linux/s390x, linux/386, linux/mips64le, linux/mips64, linux/arm/v7, linux/arm/v63.3.2 Add the environment variables as secrets
Previously, we set some environment variables with our credentials to access MinIO. When deploying an image to Kubernetes, the typical way to set sensitive information is through Secrets. Secrets is a simple way for us to set variables that are somewhat sensitive. For production deployments you should follow these good practices for Kubernetes secrets.
kubectl create secret generic dpga-pipeline-secret \
--namespace magasin-dagster \
--from-literal=FSSPEC_S3_ENDPOINT_URL=http://myminio-ml.magasin-tenant.svc.cluster.local \
--from-literal=FSSPEC_S3_KEY='minio' \
--from-literal=FSSPEC_S3_SECRET='minio123'This command will create a secret called dpga-pipeline-secret in the namespace magasin-dagster. Remember that a namespace in Kubernetes is something that can be compared to a folder.
Note that the FSSPEC_S3_ENDPOINT_URL is no longer localhost, but the URL of the minio server on the cluster. Internal names follow this pattern <service-name>.<namespace>.svc.cluster.local.
To check the secret was created you can run this command:
kubectl get secrets --namespace magasin-dagsterAnd check there is a line with dpga-pipeline-secret with 3 in the data column:
NAME TYPE DATA AGE
dagster-postgresql Opaque 1 3d22h
dagster-postgresql-secret Opaque 1 3d22h
dpga-pipeline-secret Opaque 3 3m16s
sh.helm.release.v1.dagster.v1 helm.sh/release.v1 1 3d22hTo see the contents of each data point:
kubectl get secret dpga-pipeline-secret -n magasin-dagster -o jsonpath='{.data.FSSPEC_S3_ENDPOINT_URL}' | base64 --decodeNotice the | base64 --decode, this is because the screts are encoded in base64. For example minio is encoded as bWluaW8=.
If you need to update the secret, one simple way is to delete and then add it back. To delete run the command:
# kubectl delete secret <secretname> --namespace <namespace-name>
kubectl delete secret dpga-pipeline-secret --namespace magasin-dagster3.3.3 Re-Deploy Dagster
The last thing we have to do is to re-deploy Dagster so that it includes our new pipeline.
Create a new file called dagster-helm-values.yml with the following contents:
dagster-user-deployments:
enabled: true
deployments:
- name: "dpga-pipeline-k8s"
image:
repository: "merlos/dpga-pipeline"
tag: latest
pullPolicy: Always
dagsterApiGrpcArgs:
- "--package-name"
- "dpga_pipeline"
port: 3030
envSecrets:
- name: dpga-pipeline-secret
includeConfigInLaunchedRuns:
enabled: trueThis file can also hold ConfigMaps or labels. You have more details about the dagster user deployment options
This file telling to include in the deployment our pipeline image (merlos/dpga-pipeline) as well as the environment secret envSecret called dpga-pipeline-secret.
Also we have defined in the file dagsterApiGrpcArgs. This includes the arguments for dagster api grpc, which you can get by running dagster api grpc --help. As we said earlier, it is on the deployment where we set launch command for the image. This is the command. Dagster uses Remote Procedure Calls, which for the purposes of this tutorial you can understand as an regular API to communicate the main dagster daemon and our deployments. The daemon is the long-lasting process that keeps track of the sensor,shedules, etc. And this daemon communicates with theIn our case we tell the command that Dagster uses remote procedure calls between the dagster main process and our image.
Now we have to update our kubernetes deployment to include this new pipeline (a.k.a. code location in Dagster terminology).
Go to the folder where the dagster-helm-values.yaml is located, and then run:
helm upgrade dagster magasin/dagster --namespace magasin-dagster -f ./dagster-helm-values.ymlThis will update the deployment of the dagster instance of magasin. You should see something like:
Release "dagster" has been upgraded. Happy Helming!
NAME: dagster
LAST DEPLOYED: Tue Feb 13 09:28:32 2024
NAMESPACE: magasin-dagster
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
Launched. You can access the Dagster webserver/UI by running the following commands:
export DAGSTER_WEBSERVER_POD_NAME=$(kubectl get pods --namespace magasin-dagster -l "app.kubernetes.io/name=dagster,app.kubernetes.io/instance=dagster,component=dagster-webserver" -o jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:8080 to open the Dagster UI"
kubectl --namespace magasin-dagster port-forward $DAGSTER_WEBSERVER_POD_NAME 8080:80To open the Dagster user interface of the instance running in our Kubernetes cluster we need to run
mag dagster uiNow, this will open the dagster instance in your Kubernetes cluster.
You have available the source code of the pipeline, Dockerfile, dagster-helm-values.yml in magasin’s source code repository within the folder examples/dpga-pipeline/dpga-pipeline-store-minio
3.4 Troubleshooting the deployment
In case you face any issue here you have some ways of trying to find out what’s going on. This and seeking some help on a search engine or large language model, typically helps:
3.5 Commands to inspect status
Check if everything is running fine. You can check the status of the pods in the magasin-dagster namespace
kubectl get pods --namespace magasin-dagsterNAME READY STATUS RESTARTS AGE
dagster-daemon-7c6474cbfd-7rgtr 1/1 Running 0 3h41m
dagster-dagster-user-deployments-dpga-pipeline-k8s-5kqtc 1/1 Running 0 64m
dagster-dagster-webserver-76ff9c7689-zv89b 1/1 Running 0 3h41m
dagster-postgresql-0 1/1 Running 6 (5h53m ago) 4d2h
dagster-run-745684fc-80c5-45e5-a238-ce5fdc0c0dbe-nzh8x 0/1 Error 0 124mHere you can see the run had an error.
Describe the dagster-run pod:
kubectl describe pod dagster-run-745684fc-80c5-45e5-a238-ce5fdc0c0dbe-nzh8x -n magasin-dagsterGet the logs of the run pod:
kubectl logs dagster-run-745684fc-80c5-45e5-a238-ce5fdc0c0dbe-nzh8x -n magasin-dagsterkubectl describe job dagster-run-745684fc-80c5-45e5-a238-ce5fdc0c0dbe-nzh8x -n
magasin-dagsterInspect the logs of the deployed main pod:
kubectl logs dagster-dagster-user-deployments-dpga-pipeline-k8s-5kqtc --namespace magasin-dagster2024-02-13 10:26:42 +0000 - dagster.code_server - INFO - Starting Dagster code server for package dpga_pipeline on port 3030 in process 1
2024-02-13 10:26:42 +0000 - dagster.code_server - INFO - Started Dagster code server for package dpga_pipeline on port 3030 in process 1Lastly, on the Dagster user interface (launched with mag dagster ui), in the Runs tab, within your failed run click on View run button.
4 Summary
We have done a big deal of tasks. This is, probably, the most challenging step as it requires working with many different tools and technologies (MinIO, Dagster, Helm, Kubectl, python…). However, using this setup, it offers us a lot of flexibility and allows us to scale.
Created a pipeline that loads from an API and saves the processed data as a
.parquetfile, a format that is Big Data friendly.We created a MinIO bucket where we can save the output data in a storage that is widely supported by many systems and libraries (S3 bucket).
We scheduled our pipeline to be run automatically from time to time.
Lastly, we deployed this new pipeline within our Kubernetes cluster.
5 What’s next
Go to next step, create a dashboard in Superset
Dagster has a learning curve, and it requires some work in order to get used to it, but the documentation is fairly good.
Here you have a few links to get started with dagster: