flowchart LR A(1.Manual analysis using a \nJupyter Notebook) --> B(2.Automate data ingestion with\n Dagster) B --> C(3.Create a Dashboard with\n Superset)
Tutorial overview
In this tutorial, we’ll walk you through a straightforward example we’ve created that demonstrates a typical data processing workflow. We will show you how to launch each component, explain essential concepts, but we won’t dive too deep into all the nitty-gritty details of each component.
We will follow this process simple process that is similar to what you may do in the real world:
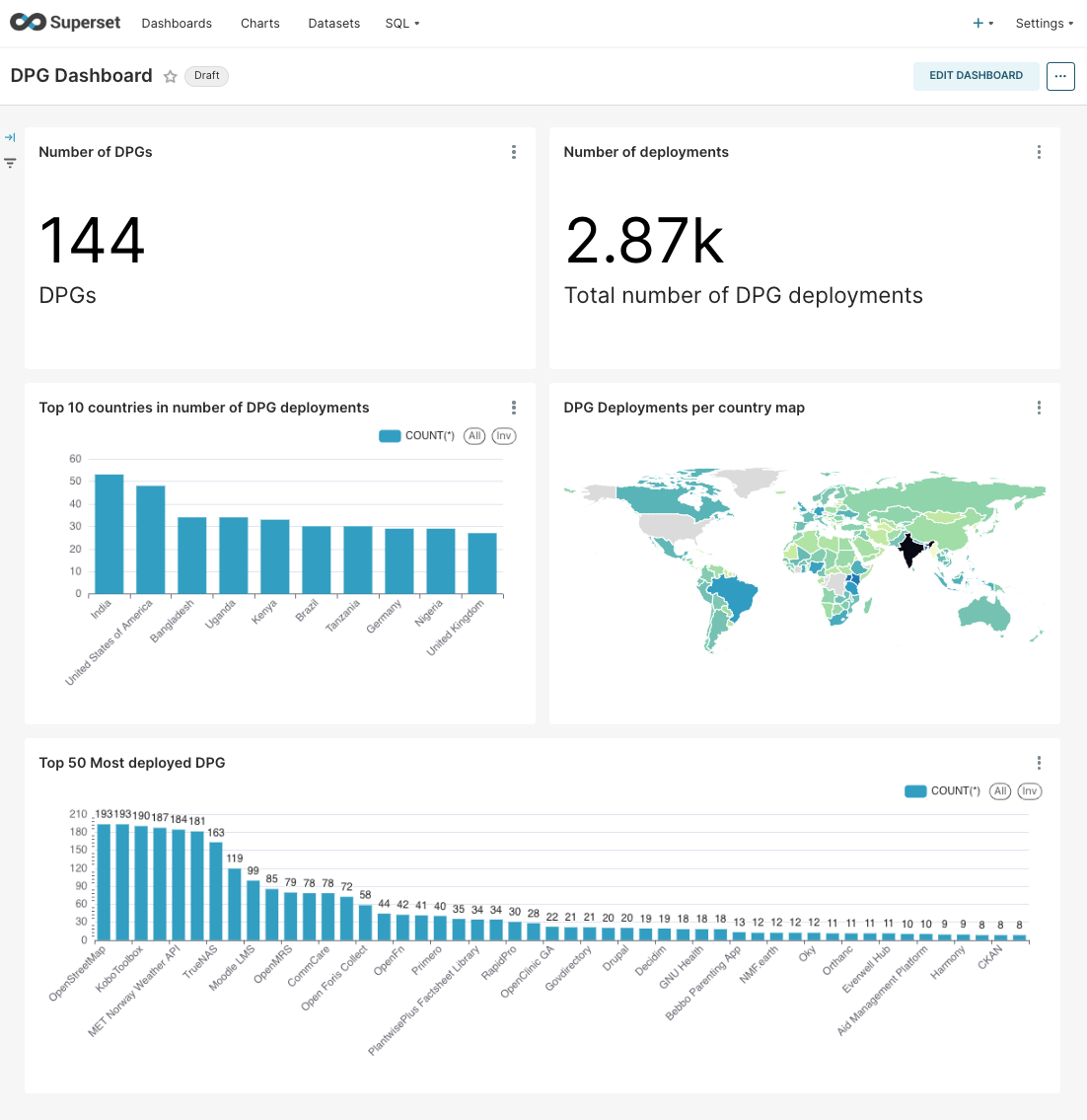
As a result you will have the following dashboard that collects data from an external datasource, and is automatically updated through an schedule:
0.1 Step 1: Exploratory data analysis in a Jupyter Notebook
Generally, before you start automating any process of regularly using some data you want to do some initial research and analysis, you want to discover and understand how the data is shaped and what kind of insights can be extract from the data you have. For that, Jupyter Notebook is a great tool. It allows you to run small pieces of code (usually Python or R) interactively in a user friendly interface.
Magasin comes with the JupyterHub, which allows different users to run jupyter notebooks on the cloud without the need of installing anything on their own system.
In this tutorial, we are going play around with one simple API, the Digital Public Goods Alliance (DPGA) API.
Digital Public Goods (DPGs) are defined as open source software, open data, open AI models, open standards and open content that adhere to privacy and other applicable laws and best practices, do no harm, and help attain the SDGs. Several international agencies, including UNICEF and UNDP, are exploring DPGs as a possible approach to address the issue of digital inclusion, particularly for children in emerging economies.
From the data that we fetch from the API, we are going to query the data to derive some insights on how many DPGs are available, in which countries they are being deployed, where are they developed, what types of licenses are more popular…
Jupyter Notebooks are excellent for an initial analysis, but there are many use cases in which you may need to repeat the same process periodically. In our example, we may want to track if new DPGs are announced or what are the trends in terms of deployments. This is when the next steps of the process are useful.
0.2 Step 2: Automate data ingestion with Dagster
Automating is great, it frees us the burden of needing to repeat work. In our example, we will automate the ingestion and transformation of the DPGA API data. The data as it is served by the API is not fully ready to be analyzed, we need to perform some transformations to make it ready to be visualized.
We did the heavy-lifting interactively with the first analysis and now we just need to convert it to a dagster pipeline.
Dagster is a pipeline orchestrator, which basically helps us to manage the ingestion of data from multiple data sources.
The advantages of using a framework like dagster is that it will allow us to do things in a structured way which will allow you to scale and monitor workflows more efficiently. If you ask anyone that has been gathering data from multiple data sources they will tell you that it can become a daunting task if you don’t do it systematically. Dagster provides you a good starting point.
What usually happends when you start automating stuff is that:
It starts simple but with time, you add more and more data sources that have dependencies between them. If it is not done properly you end up with a mess. Dagster provides us a framework to prevent that.
It may eventually break. Data sources may change with time and subsequently your pipelines may break. For instance, DPGA may update their API and causing the downstream automation to fail. Dagster enhances the monitoring capabilities for data pipelines.
The cool thing about Dagster, is that it uses the Python programming language too, so most of the work we did in the Jupyter Notebook is reusable.
In the magasin architecture, usually data assets are stored in files. In particular, we recommend the use of Apache parquet file format for storing the datasets.
Parquet is a columnar storage file format that is commonly used in the Big Data ecosystem. It is designed to efficiently store and process large amounts of data.
Using Parquet to store datasets is beneficial because it optimizes storage, improves query performance, and enhances the overall efficiency of data processing. Its compatibility with popular big data processing frameworks and support for schema evolution make it a versatile choice for storing large-scale, evolving datasets in data lakes and data warehouses.
In this step, we will leverage another component of magasin to help us maintain a cloud agnostic architecture. It is called MinIO and gives us an Amazon S3 compatible file store.
Thanks to MinIO, regardless of what infrastructure you’re using, your pipelines will work the same and you do not need to adapt how you store the data. Using files, compared to using a traditional SQL schema, allows you to store not only structured tabular data, but also images or documents. It simplifies also the governance of the datasets as the problem of sharing is reduced to assigning file/folder permissions.
To maintain a vendor-agnostic architecture, we leverage MinIO. However, in alignment with our loosely coupled design, you have the flexibility to bypass this component if you find alternative methods more suitable for storing your ingested data. This decision may be based on better alignment with your existing processes or specific use case requirements.
For instance, instead of MinIO, you can directly utilize a vendor-specific object store like Azure Blobs, Amazon S3, or Google Cloud Storage. Alternatively, you may choose to write your data into a database, such as DuckDB or PostgreSQL.
0.3 Step 3: Create a dashboard with Superset
Dagster allows you to gather the data and transform it into something that can be displayed, but it does not come with advanced visualization capabilities. For that we need a tool that has better charting capabilities, and allows us to interact with the data, that is a Business Intelligence (BI) tool.
magasin ships with Apache Superset, which allows you to author dashboard and reports from a wide array of beautiful visualizations.
In this last step, we will create a dashboard to showcase the data.
Earlier, we already did the heavy-lifting in the first step using the notebook environment, so now we just need familiar with Superset’s intuitive interface for visualizing datasets and crafting interactive dashboards.
1 What’s next?
Now that you have an overview, let’s start working with magasin: